
The New Stack: Origins

(This piece is the first in a series — written in collaboration with Bhushan Nigale — that explores the evolution of the software technology stack and software development methodologies in the last two decades. It examines why the “traditional” stack could not meet the needs of a new class of applications that began to emerge in the late nineties, and outlines the characteristics of the “new” stack we see today.)
One of the privileges of working in the same industry for a couple of decades is that you can look back and reflect upon the changes you’ve seen there. But this isn’t something that comes easily to us. Why are things the way they are in software? is a question we don’t ponder enough. For youngsters entering the industry, current challenges may seem more relevant to study than past trials. And for veterans who’ve seen it all, the present carries a cloak of inevitability that makes looking at history seem like an academic exercise.
But it doesn’t have to be that way. Understanding the forces that led to the evolution in software we’ve seen in these last two decades can help us make better decisions today. And understanding the consequences of these changes can help us take the long view and shape things going forward. To see how, let’s begin with the technology stack that was common two decades ago.
The Traditional stack
When I started working in the enterprise software industry back in the late nineties, the software we built was deployed on large physical servers that were located ‘on-premise’. The application was a monolith, and it used an SQL-based relational database. The fat-client user-interface ran on PCs or laptops. Most of this stack was built on proprietary software. Put simply, this is how the stack looked like:
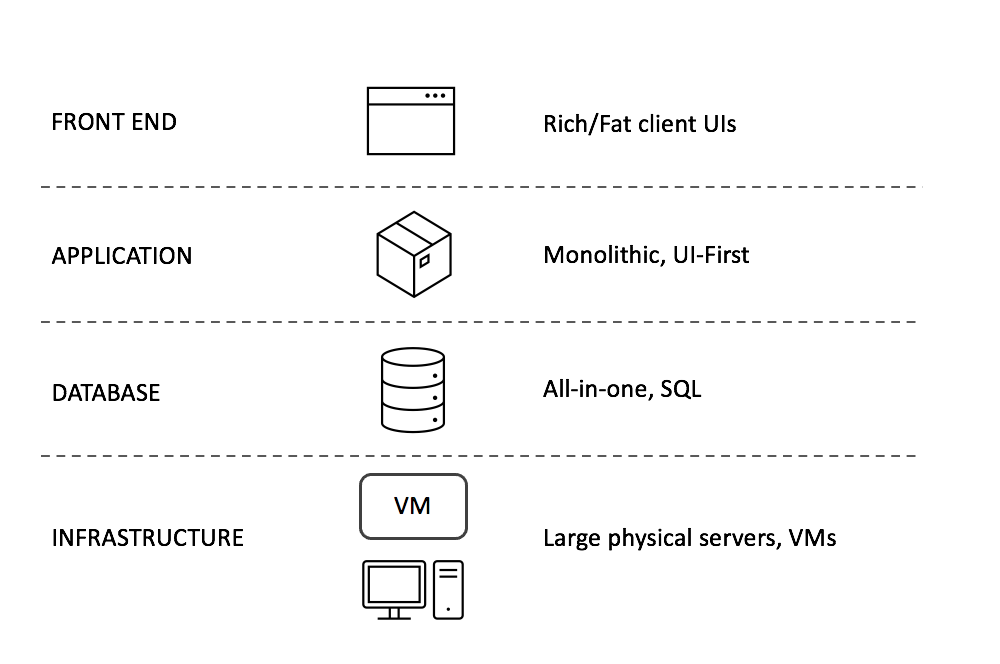
This was the state of the client-server computing model used in business applications in the nineties. At SAP, where I worked, the client was based on a proprietary framework called SAPGui; the application server was another proprietary piece of software that enabled thousands of users working in parallel; the database layer was open (you could use options like Microsoft SQL server, Oracle DB, or IBM DB2, among others); and the infrastructure beneath was an expensive server (like IBM AS/400 or Sun SPARC) that sat in the customer’s data center.
This architecture was optimized for the needs of business applications that evolved in the nineties, and such a stack — from SAP or other vendors in that era — is still used in a majority of on-premise installations. But in the second half of the nineties a different story was unfolding elsewhere.
Internet-based applications were gaining traction as the dot-com era blossomed, fell dramatically, then picked up again (no longer bearing the ‘dot com’ label). And for those applications, the traditional stack proved woefully inadequate. The reasons included cost, availability, performance, flexibility, reliability, and speed: key demands placed by the new types of applications being built on the internet.
The internet breaks the traditional stack
The internet ushered in a scale that was unimaginable in on-premise enterprise software. Websites like Google, eBay, and Amazon had to serve a large number of concurrent users and cope with wide variations in demand. With the traditional stack, adding more capacity to an existing server soon reached its limits, and adding new servers was both expensive and time-consuming. In the new business context, infrastructure costs could no longer grow linearly with user growth: applications needed an architecture that enabled close to zero marginal cost of adding a new user; the old way of adding expensive hardware was unviable.
The internet also placed a much higher demand on availability: these applications needed to be “always on”. Initially a requirement mainly with B2C applications, availability caught up with the B2B world as consumerization of IT gained speed. Soon ‘continuous availability’ turned into a competitive differentiator for businesses that moved (partially or fully) to the web. Five nines or six nines (99.9999 % availability) became the benchmarks, and a new architecture was needed to achieve this level of availability without driving up costs. Again, the old way of installing expensive servers for failover was simply too expensive and inefficient.
The need to scale applications better also arose due to performance expectations from internet-based (and later mobile) applications. E-commerce applications also saw peak usage in some periods (like Christmas or Black Friday), and others had ad hoc expectations (like planning an ad campaign for a few weeks). Meeting this unpredictable demand needed a different level of flexibility in resource allocation, something that the traditional stack — and hardware-based methods — could simply not offer.
Businesses that moved to the internet also had to evolve much faster than the systems of record (built on the traditional stack) that had dominated the previous era of business applications. Parts of the application that needed more frequent changes had to be deployed independently — and at a different pace — from other slow-moving parts. This was not possible with the monolithic applications built on the traditional stack: it required a new architecture that allowed teams to build and deploy smaller pieces at a faster pace. (It wasn’t just the technology stack that was inadequate — the traditional waterfall model could also not cope with this pace of change and the flexibility this new world demanded. This parallel evolution of development practices will be discussed in a separate article.)
The internet also spawned companies with new business models. And such companies, based entirely on the internet, demanded a different level of maturity from the technology stack. Resilience in particular was key when the entire business was on the internet, and this needed a fault-tolerant architecture. The traditional stack fared poorly in this matter, as there was little or no redundancy in the setup.
As internet-based applications grew in popularity, their massive adoption resulted in huge volumes of data that needed to be managed. Here again was a need that the traditional stack was unable to meet, as the architecture — with hard-to-scale relational databases — could not cope with adding more storage space at reasonable costs and with the required agility.
Mobile and Cloud
With the rise of smartphones, applications on mobile devices pushed the above expectations further. For apps running on mobile devices, the stack had to support even better response times. Mobile user experiences also demanded native user interfaces (specific to the device) and an always-on expectation. The smartphone era led to an explosion of B2C applications, which fueled innovations in user interface technologies at a pace that the old (proprietary, fat-client) UI frameworks could not match.
The growth of the public cloud, driven initially by AWS, accelerated the trends that had begun with the first generation of internet-based applications.
The traditional stack simply could not offer the capabilities such cloud-native and mobile-enabled applications needed. A new architecture evolved with the growth of these demands.
Hardware costs
The emergence of low-cost, commodity hardware (that could be put together to build large distributed systems) tilted the scales further towards this new architecture. Innovations such as Google File System (2003) and Amazon’s DynamoDB (2007) were built on this foundation of cheap hardware, which were just small servers with basic compute and storage. As we will see in the next section, one key aspect of this new architecture was that it was distributed, and these innovations laid the foundation for the architecture we see in the cloud today.
The New Stack
So what does the new stack — one that can meet the above demands — look like these days? The infrastructure underneath the application is a cluster of distributed nodes that host one or more containers. The application itself is split into microservices that communicate over the network through API calls. All-in-one, relational databases have been superseded by single-purpose NoSQL ones. User interfaces are largely browser-based or natively built for mobile environments. New interfaces like chat and voice are going mainstream. And APIs are first-class citizens by themselves.
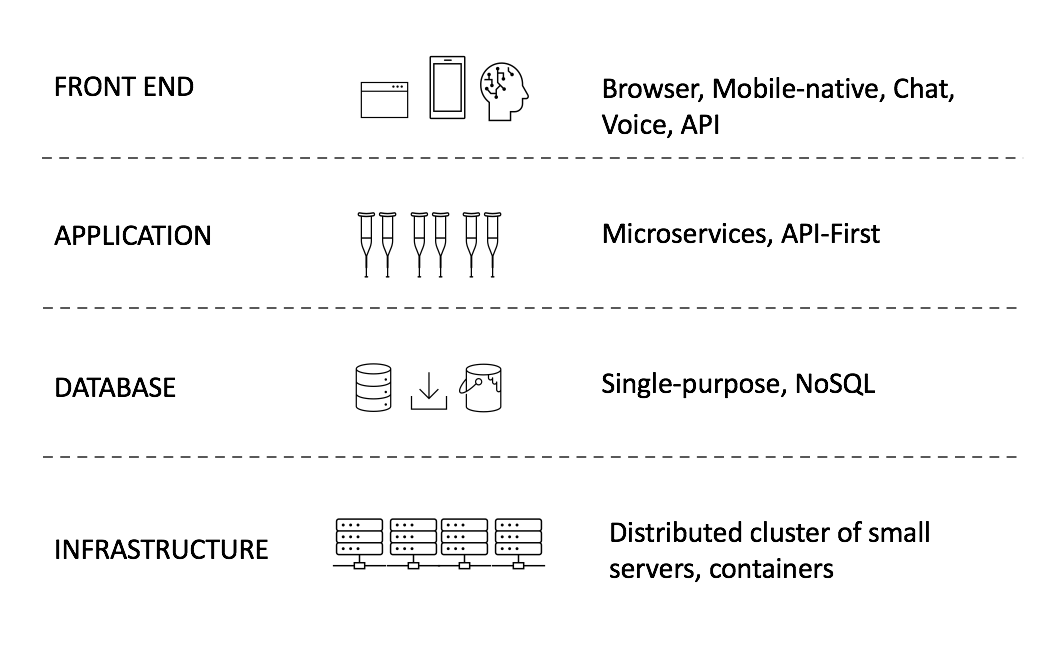
Of course, the new stack has not entirely replaced the old one. New applications built today may still have elements of the traditional stack: monolithic applications, for instance, remain relevant in contexts where microservices add unnecessary overheads. But today if one wants to build a cloud-native application that must scale to a large number of users in a cost-efficient, flexible, and resilient manner, it will contain most of the new stack elements.
Key characteristics of the new stack
While the above stack picture outlines the individual elements of the new stack, there are some common themes that run across these layers. Let’s look at some of these.
The new stack is distributed. The infrastructure layer is a cluster of smaller servers made of commodity hardware. The application layer is a collection of microservices running in that cluster, each of which may consume services from anywhere in the cloud. The database – and the data – is spread across the cluster. These elements make the new stack more loosely coupled.
The new stack is all about APIs. Each layer in the stack is a collection of APIs that define the behaviour of that layer. The new stack is also ‘software-defined’: everything is code, including the infrastructure.
The breakdown of the traditional stack into smaller pieces has led to focused solutions that solve a more narrowly defined problem with better efficiency. NoSQL databases (like graph db, document db, etc) are good examples of such specialisation, but it can also be seen in the UI layer with specific (native) user-interfaces that offer a better user experience than a general-purpose client. In other words, the new stack offers specialised/single-purpose solutions over all-in-one/general-purpose solutions we saw earlier.

The new stack relies heavily on open-source software. The breakdown of the stack into smaller pieces was in part the result of and in part fueled by the explosion of open-source projects that offered smaller, reusable parts and specialised solutions (like MongoDB for document storage, Infrastructure-as-Code offerings like Terraform, etc). In fact, the broad adoption of the technology stack we see today owes a lot to open source. It offered a more pragmatic route towards standardisation, as large companies pooled their resources into open-source projects for technologies they needed. This increased the chances of broader adoption of such technologies. Today open-source components are present across all layers of the new stack: it’s hard to imagine this stack without them.
Given all this, it is now common to have a combination of technologies (often from different open-source or 3rd-party vendors) coming together within one application. So the new stack is a lot more heterogeneous than the traditional one.
In a way, significant parts of the new stack can be thought of as a frame rather than fixed architectural entities in themselves. Container technology now enables us to use technologies of our choosing to build parts of the stack and bundle them into containers. These technologies can change over time, but the container abstraction remains. APIs (now spread across all the layers) abstract consumers from the concrete choices made during the implementations, choices that may change in future. Such approaches make the new stack more open to changes than the traditional one.
Conclusion
The new stack represents a radical shift from the traditional one that was common two decades ago. And it solves the problems the traditional stack is unable to, in the context of demands we saw above — demands that originated from internet/mobile/cloud-based applications. The new stack’s distributed nature (coupled with its API centric and ‘software-defined’ approaches) allows applications to scale better (i.e., faster, cheaper, and with greater flexibility), offer higher performance, improved reliability, and better ways to manage huge data volumes. The microservices approach enables applications to evolve parts of the application faster, offer better reliability, and enable large distributed setups to work more efficiently through small teams. The division of the new stack into smaller parts enables it to address niche problem spaces, such as offering databases for specific use-cases or native user interfaces for a given platform — and many of these solutions today come from open source projects that have revolutionised the way the components of this new stack are built.
But what have been the consequences of this radical shift? What challenges does the new stack bring with it? How will this architecture evolve? Is the traditional stack really obsolete? These are some of the questions we’ll explore in the upcoming articles in this series. A parallel track — written by Bhushan Nigale — will trace the evolution of development and operations practices across these two decades.